Parallel Fortran, C and C++ Compilers & Tools for Programming HPC Clusters
In combination with the Linux or Windows HPC Server 2008 operating systems, the PGI CDK® Cluster Development Kit® compilers and development tools enable use of networked clusters of AMD or Intel x64 processor-based workstations and servers to tackle the largest scientific computing applications. For Linux, the PGI CDK includes pre-configured versions of MPI for Ethernet or InfiniBand, and a pre-configured batch queueing system. On Windows HPC Server 2008, the PGI CDK integrates with MSMPI and the job scheduler to enable development, debugging and tuning of high-performance MPI or hybrid MPI/OpenMP applications written in Fortran, C or C++.
Parallel Fortran, C and C++ Compilers
 PGI compilers offer world-class performance and features including auto-parallelization for multicore, OpenMP directive-based parallelization, and support for the PGI Unified Binary™ technology. The PGI Unified Binary streamlines cross-platform support by combining into a single executable file code optimized for multiple x64 processors. This gives you the assurance that your applications will run correctly and with optimal performance regardless of the type of x64 processor on which they are deployed. PGI's state-of-the-art compiler optimization technologies include SSE vectorization, auto-parallelization, inter-procedural analysis and optimization, memory hierarchy optimizations, function inlining (including library functions), profile feedback optimization, CPU-specific micro-architecture optimizations and more. PGI is the ideal solution for migrating compute-intensive legacy applications from RISC/UNIX servers and workstations to 64-bit Linux or Windows clusters.
PGI compilers offer world-class performance and features including auto-parallelization for multicore, OpenMP directive-based parallelization, and support for the PGI Unified Binary™ technology. The PGI Unified Binary streamlines cross-platform support by combining into a single executable file code optimized for multiple x64 processors. This gives you the assurance that your applications will run correctly and with optimal performance regardless of the type of x64 processor on which they are deployed. PGI's state-of-the-art compiler optimization technologies include SSE vectorization, auto-parallelization, inter-procedural analysis and optimization, memory hierarchy optimizations, function inlining (including library functions), profile feedback optimization, CPU-specific micro-architecture optimizations and more. PGI is the ideal solution for migrating compute-intensive legacy applications from RISC/UNIX servers and workstations to 64-bit Linux or Windows clusters.
About PGI Accelerator Compilers
With Release 9.0, PGI Fortran and C compilers support directive-based programming of x64+NVIDIA Linux systems; PGF95 and PGCC accelerator compilers are supported on all Intel and AMD x64 processor-based systems with CUDA-enabled NVIDIA GPUs.
PGI Accelerator compilers are included in all PGI Linux download packages. Either trial license keys or updated permanent license keys are required to enable them. Please see the PGI Accelerator page for more information.
The PGDBG OpenMP/MPI Debugger
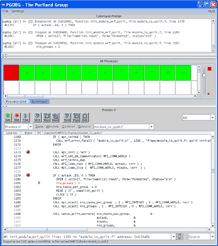 Debugging a cluster MPI application can be extremely challenging. The PGDBG® debugger provides a comprehensive set of graphical user interface (GUI) elements to assist you in this process. PGDBG provides the ability to separately debug and control OpenMP threads and MPI processes on your Linux or Windows cluster. Step, Next, Break, Halt, Wait or Continue OpenMP threads or MPI processes individually, as a group, or in user-defined process/thread subsets. PGDBG can even display the state of MPI message queues, enabling you to quickly isolate and resolve message-passing deadlock bugs. Using a single integrated multi-process debugging window, PGDBG provides precise control and feedback on the state of every MPI process and OpenMP thread simultaneously, with fully integrated capabilities for debugging hybrid parallel programs that use MPI message-passing between nodes and OpenMP shared-memory parallelism within a multicore processor-based cluster node.
Debugging a cluster MPI application can be extremely challenging. The PGDBG® debugger provides a comprehensive set of graphical user interface (GUI) elements to assist you in this process. PGDBG provides the ability to separately debug and control OpenMP threads and MPI processes on your Linux or Windows cluster. Step, Next, Break, Halt, Wait or Continue OpenMP threads or MPI processes individually, as a group, or in user-defined process/thread subsets. PGDBG can even display the state of MPI message queues, enabling you to quickly isolate and resolve message-passing deadlock bugs. Using a single integrated multi-process debugging window, PGDBG provides precise control and feedback on the state of every MPI process and OpenMP thread simultaneously, with fully integrated capabilities for debugging hybrid parallel programs that use MPI message-passing between nodes and OpenMP shared-memory parallelism within a multicore processor-based cluster node.
The main PGDBG window displays Fortran, C or C++ program source code, optionally interleaved with the corresponding x64 assembly code. Sub-windows enable watch points, register state dumps, and execution of a sequence of user-defined commands at every break point. The main window includes one-touch buttons for the most common debugging commands. A simple and intuitive process/thread grid makes it easy to change the context of the source window and all sub-windows from one process to another with a single mouse click, greatly simplifying control over individual or collective OpenMP threads and MPI processes. PGDBG is interoperable with the Microsoft Visual C++ compiler on Windows HPC Server 2008, and with the GNU gcc/g++ compilers on Linux.
View the PGDBG demo (approximately seven minute Flash movie).
The PGPROF OpenMP/MPI Profiler
PGPROF® is a powerful and easy-to-use interactive postmortem statistical analyzer for MPI parallel and OpenMP thread-parallel programs running on Linux or Windows clusters. Use PGPROF to visualize and diagnose the performance of the components of your program. Using tables and graphs, PGPROF associates execution time with the source code and instructions of your program, allowing you to see where and how execution time is spent. Through resource utilization data and compiler feedback information, PGPROF also provides features for helping you to understand why certain parts of your program have high execution times.
You can use PGPROF to analyze programs on multicore SMP Servers, distributed-memory clusters and hybrid clusters where each node contains multicore x64 processors. Use the PGPROF profiler to profile parallel programs, including multiprocess MPI programs, multi-threaded OpenMP programs, or a combination of both. PGPROF allows profiling at the function, source code line, and assembly instruction level for PGI-compiled Fortran, C and C++ programs. PGPROF provides views of the performance data for analysis of MPI communication, multiprocess and multi-thread load balancing, and scalability.
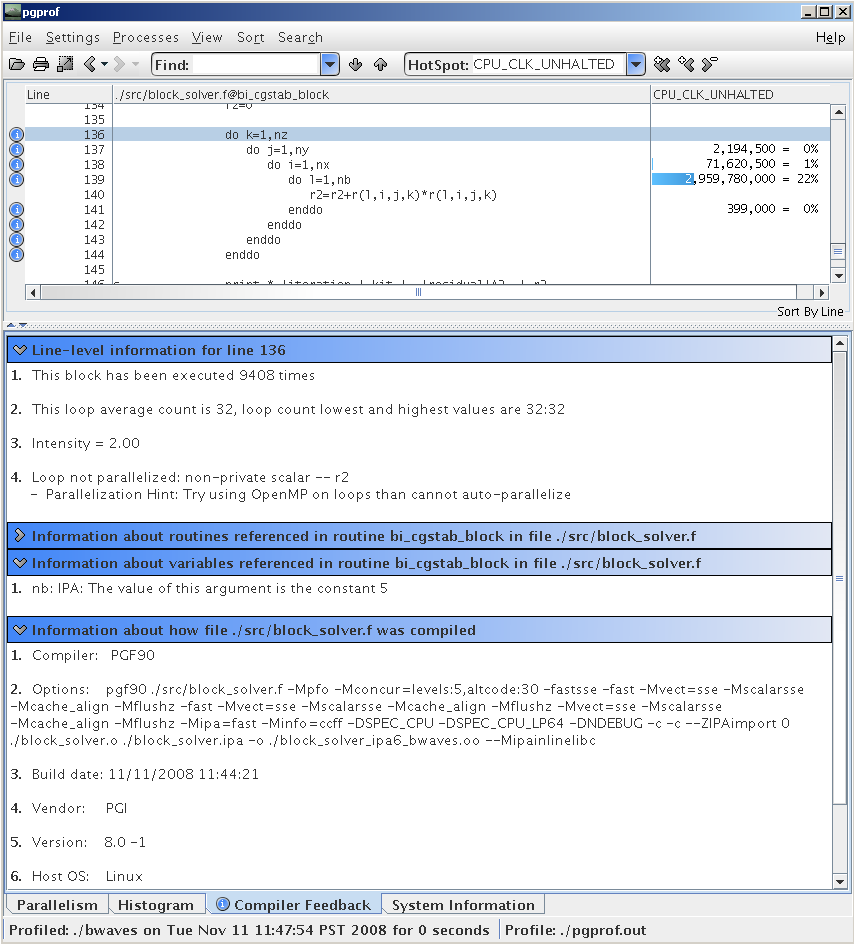
Using the Common Compiler Feedback Format (CCFF), PGI compilers save information about how your program was optimized, or why a particular optimization was not made. PGPROF can extract this information and associate it with source code and other performance data, allowing you to view all of this information simultaneously. PGPROF also supports a feedbackonly mode, which allows you to browse compiler feedback associated with a CCFF-enabled binary executable in the absence of a performance profile.
Each performance profile depends on the resources of the system where it is run. PGPROF provides a summary of the processor(s) and operating system(s) used by the application during any given performance experiment
View full size image
PGPROF provides the information you need to determine which functions and lines in an application are consuming the most execution time. Combined with the feedback features of the PGI compilers, PGPROF will enable you to maximize vectorization and performance on a single x64 processor core. PGPROF exposes performance bottlenecks in a cluster application by presenting the number of calls, aggregate message size and execution time of individual MPI function calls on a line by line basis.
Using PGPROF, you can merge trace files from multiple runs on different numbers of nodes to perform scalability analysis on your MPI or OpenMP application at the application, function or line level. Scalability analysis allows you to quickly see which parts of your application are barriers to scalable performance, and where your parallel tuning efforts should be focused. PGPROF, displays information in easy-to-use formats such as bar-charts, percentages, counts or seconds and displays profiles using graphical histograms.
PGI Cluster Development Kit Key Features
- Floating multi-user seats for the PGI parallel PGF95™, PGCC® and PGC++® compilers. World-class single core and multicore processor performance
- Full native support for OpenMP directive- and pragma-based SMP or multicore parallelization in PGF95, PGCC and PGC++
- Auto-parallelization for the latest AMD Opteron and Intel Core 2 multicore processors
- Graphical PGDBG parallel debugger and PGPROF parallel performance profiler for auto-parallel, thread-parallel, OpenMP and MPI programs
- Pre-configured MPI message-passing libraries and utilities for Linux
- Pre-configured batch queueing system to manage the workload and throughput on a Linux cluster
- Optimized BLAS and LAPACK math libraries
- Comprehensive support for all major Linux distributions and Microsoft Windows HPC Server 2008
- Installation utilities to simplify the setup and management of your Linux cluster
- PGI Roll option*.
MPI Support
On Linux, the OpenMP and MPI parallel PGDBG debugger and PGPROF performance profiler included with the PGI CDK support MPICH, MPICH2, HP-MPI and OpenMPI over Ethernet and MVAPICH over InfiniBand clusters. MPICH (including MPICH2) was developed at the Argonne National Laboratory. MPICH is an open source implementation of the Message-Passing Interface (MPI) standard. MPICH is a full implementation of MPI, so your existing MPI applications will port easily to your Linux cluster using the PGI CDK.
MVAPICH, the "MPI over InfiniBand, iWARP and RDMA-enabled Interconnects" project is led by Network-Based Computing Laboratory, Department of Computer Science and Engineering at Ohio State University.
On Windows, the OpenMP and MPI Parallel PGDBG debugger and PGPROF performance profiler included with the PGI CDK support MSMPI.
Request a 30 day trial of the PGI CDK by completing the PGI CDK Evaluation Request Form.
*About the PGI Roll—The PGI Roll is distributed through Clustercorp. Access to the software requires the purchase of Clustercorp Rocks+ license. The PGI Roll contains software only. A valid PGI license is required to use the software. A valid PGI CDK license is required to enable remote MPI debugging and profiling.
Technical Features
A partial list of technical features supported includes the following:
- PGF95 OpenMP and auto-parallel Fortran 90/95 compiler
- PGF77 OpenMP and auto-parallel FORTRAN 77 compiler
- PGHPF data parallel compiler with native full HPF language support (Linux only)
- PGC++ OpenMP and auto-parallel ANSI C++ compiler
- PGCC OpenMP and auto-parallel ANSI/K&R C99 compiler
- PGDBG graphical Cluster MPI and OpenMP debugger
- PGPROF graphical Cluster MPI and OpenMP performance profiler
- Full 64-bit support on AMD64 and Intel 64 processors
- Includes separate 64-bit x64 and 32-bit x86 development environments and compilers
- Optimizing 64-bit code generators with automatic or manual platform selection
- Intel 64 and AMD Opteron optimizations including SSE/SSE2/SSE3/SSSE3/SSE4.1/SSE4.2, SSE4a/ABM, prefetching, use of extended register sets, and 64-bit addressing
- Executables generated by PGI's 32-bit x86 compilers can run unchanged on AMD64 or Intel 64 processor-based systems
- Large file (> 2GB) support in Fortran on 32-bit x86 systems
- -r8/-i8 compilation flags, 64-bit integers
- Full support for Fortran 95 extensions and comprehensive support for Fortran 2003.
- Full support for OpenMP 3.0
- Includes optimized ACML (LAPACK/BLAS/FFT) math library supported on all targets
- Highly tuned Intel MMX and SSE intrinsics library routines (C/C++ only)
- One pass interprocedural analysis (IPA)
- Interprocedural optimization of libraries
- Profile feedback optimization
- Function inlining including library functions
- Enhanced auto-parallelization of loops specifically optimized for multicore processors
- Tuning for nonuniform memory access (NUMA) architectures
- Vectorization, loop interchange, loop splitting
- Memory heirarchy and memory allocation optimizations including huge pages support
- Loop unrolling, loop fusion, and cache tiling
- Support for creating shared objects on Linux and DLLs on Windows
- Cray/DEC/IBM extensions (including Cray POINTERs & DEC STRUCTURES/UNIONS)
- Support for SGI-compatible DOACROSS in PGF77 and PGF95, and for SGI-compatible parallelization pragmas in PGCC and PGC++
- Byte swapping I/O for RISC/UNIX interoperability
- Integrated cpp preprocessing
- Threads-based auto-parallelization using PGF77, PGF95, PGCC and PGC++
- Process/CPU affinity support in SMP/OpenMP applications
- Full support for Common Compiler Feedback Format compiler optimization listings
- Network installation option for large installations running multiple operating systems
- Parallelization of irregular DO loops, FORALLs, and array assignments
- User modules simplify switching between multiple compiler environments/versions
- Documentation PGI User's Guide, PGI Tools Guide, PGI CDK Installation Notes, and PGI CDK Release Notes.
- Fully interoperable with gcc, g77, and gdb
- Unconditional 30 day money back guarantee
System Requirements
- Front-end Node: 64-bit x64 or 32-bit x86 processor-based workstation or server with one or more AMD Opteron or Intel Core 2 microprocessors.
- Cluster Nodes: 64-bit x64 or 32-bit x86 processor-based workstation or server with one or more AMD Opteron or Intel Core 2 microprocessors.
Note: Heterogeneous systems that include both 32-bit and 64-bit processor-based workstations or servers are not supported.
- Network: Standard TCP/IP network such as Ethernet, Fast Ethernet or Gigabit Ethernet; high-performance InfiniBand network. Preferred configuration is a dedicated private network interconnecting the cluster nodes, with the designated front-end node also networked to a general purpose network.
- Operating System: Linux—On 32-bit x86 processor-based systems, the software must be co-installed with a version of the Linux operating system with kernel revision 2.4.18 or higher, On 64-bit processor-based systems, the software must be co-installed with 64-bit Linux with kernel revision 2.4.19 or higher.
Windows—HPC Server 2008 or Compute Cluster Server 2003.
- Memory: Minimum 1 GB per cluster node. 2 GB recommended for front-end node.
- Hard Disk: 800 MB on front-end node; 50 MB on each cluster node.
- Other: Web browser and Adobe Acrobat Reader for viewing online documentation.





{kind=link}